OpenAI’s new ChatGPT image generator makes faking photos easy
I see barbarian people
OpenAI’s new ChatGPT image generator makes faking photos easy
New GPT Image 1.5 allows more detailed conversational image editing, for better or worse.

Learn more
For most of photography’s roughly 200-year history, altering a photo convincingly required either a darkroom, some Photoshop expertise, or, at minimum, a steady hand with scissors and glue. On Tuesday, OpenAI released a tool that reduces the process to typing a sentence.
It’s not the first company to do so. While OpenAI had a conversational image-editing model in the works since GPT-4o in 2024, Google beat OpenAI to market in March with a public prototype, then refined it to a popular model called Nano Banana image model (and Nano Banana Pro). The enthusiastic response to Google’s image-editing model in the AI community got OpenAI’s attention.
OpenAI’s new GPT Image 1.5 is an AI image synthesis model that reportedly generates images up to four times faster than its predecessor and costs about 20 percent less through the API. The model rolled out to all ChatGPT users on Tuesday and represents another step toward making photorealistic image manipulation a casual process that requires no particular visual skills.

GPT Image 1.5 is notable because it’s a “native multimodal” image model, meaning image generation happens inside the same neural network that processes language prompts. (In contrast, DALL-E 3, an earlier OpenAI image generator previously built into ChatGPT, used a different technique called diffusion to generate images.)
This newer type of model, which we covered in more detail in March, treats images and text as the same kind of thing: chunks of data called “tokens” to be predicted, patterns to be completed. If you upload a photo of your dad and type “put him in a tuxedo at a wedding,” the model processes your words and the image pixels in a unified space, then outputs new pixels the same way it would output the next word in a sentence.
Using this technique, GPT Image 1.5 can more easily alter visual reality than earlier AI image models, changing someone’s pose or position, or rendering a scene from a slightly different angle, with varying degrees of success. It can also remove objects, change visual styles, adjust clothing, and refine specific areas while preserving facial likeness across successive edits. You can converse with the AI model about a photograph, refining and revising, the same way you might workshop a draft of an email in ChatGPT.
Fidji Simo, OpenAI’s CEO of applications, wrote in a blog post that ChatGPT’s chat interface was never designed for visual work. “Creating and editing images is a different kind of task and deserves a space built for visuals,” Simo wrote. To that end, OpenAI introduced a dedicated image creation space in ChatGPT’s sidebar with preset filters and trending prompts.
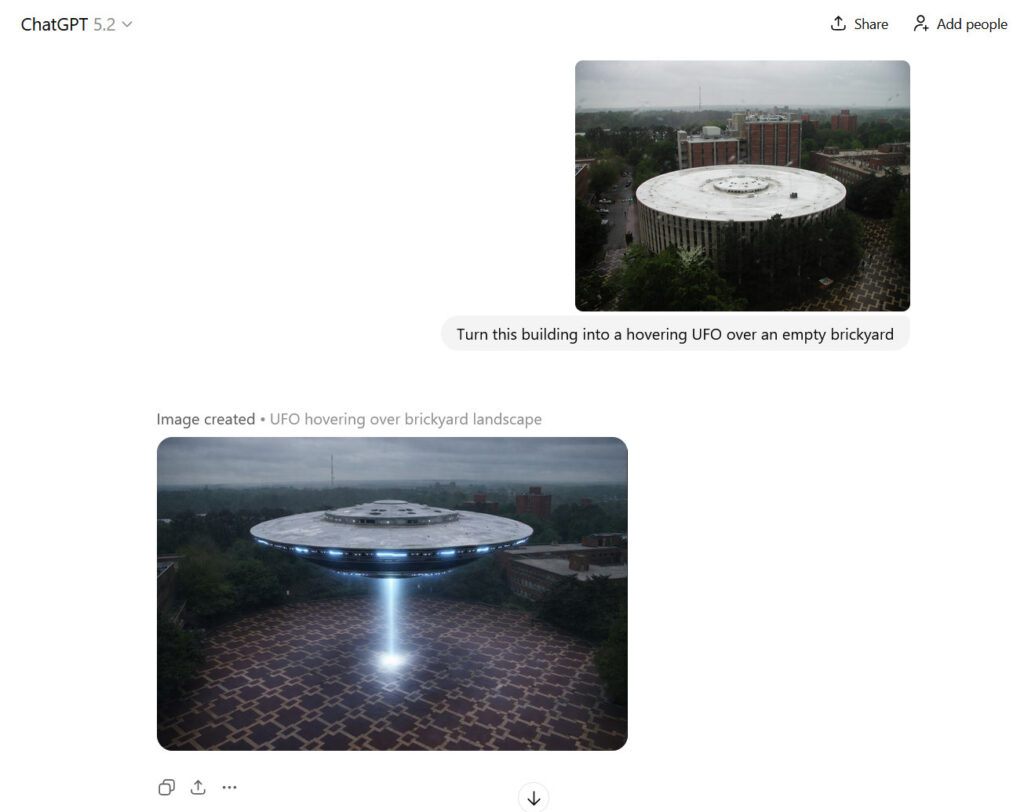
The release’s timing seems like a direct response to Google’s technical gains in AI, including a massive growth in chatbot user base. In particular, Google’s Nano Banana image model (and Nano Banana Pro) became popular on social media after its August release, thanks to its ability to render text relatively clearly and preserve faces consistently across edits.
OpenAI’s previous token-based image synthesis model could make some targeted edits based on conversational prompts, but it often changed facial details and other elements that users might have wanted to keep. GPT Image 1.5 appears designed to match the editing features that Google already shipped. But if you happen to prefer the older ChatGPT image generator, OpenAI says the previous version will remain available as a custom GPT (for now) for users who prefer it.
The friction keeps dropping
GPT Image 1.5 is not perfect. In our brief testing, it didn’t always follow prompting directions very well. But when it does work, the results seem more convincing and detailed than OpenAI’s previous multimodal image model. For a more detailed comparison, a software consultant named Shaun Pedicini has put together an instructive site (“GenAI Image Editing Showdown”) that conducts A/B testing of various AI image models.
And while we’ve written about this a lot over the past few years, it’s probably worth repeating that barriers to realistic photo editing and manipulation keep dropping. This kind of seamless, realistic, effortless AI image manipulation may prompt (pun intended) a cultural recalibration of what visual images mean to society. It can also feel a little scary, for someone who grew up in an earlier media era, to see yourself put into situations that didn’t really happen.

For most of photography’s history, a convincing forgery required skill, time, and resources. Those barriers made fakery rare enough that we could treat many photographs as a reasonable proxy for truth, although they could be manipulated (and often were). That era has ended due to AI, but GPT Image 1.5 seems to remove yet more of the remaining friction.
The capability to preserve facial likeness across edits has obvious utility for legitimate photo editing and equally obvious potential for misuse. Image generators have already been used to create non-consensual intimate imagery and impersonate real people.

With those hazards in mind, OpenAI’s image generators have always included a filter that usually blocks sexual or violent outputs. But it’s still possible to create embarrassing images of people without their consent (even though it violates OpenAI’s terms of service) while avoiding those topics. The company says generated images include C2PA metadata identifying them as AI-created, though that data can be stripped by resaving the file.
Speaking of fakes, text rendering has been a long-standing weakness in image generators that has slowly gotten better. By prompting some older image synthesis models to create a sign or poster with specific words, the results often come back garbled or misspelled.
OpenAI says GPT Image 1.5 can handle denser and smaller text. The company’s blog post includes a demonstration where the model generated an image of a newspaper with a multi-paragraph article, complete with headlines, a byline, benchmark tables, and body text that remains legible at the paragraph level. Whether this holds up across varied prompts will require broader testing.

While the newspaper in the example looks fake now, it’s another step toward the potential erosion of the public’s perception of the pre-Internet historical record as image synthesis becomes more realistic.
OpenAI acknowledged in its blog post that the new model still has problems, including limited support for certain drawing styles and mistakes when generating images that require scientific accuracy. But they think it will get better over time. “We believe we’re still at the beginning of what image generation can enable,” the company wrote. And if the past three years of progress in image synthesis are any indication, they may be correct.
 Benj Edwards
Senior AI Reporter
Benj Edwards
Senior AI Reporter
Benj Edwards
Senior AI Reporter
Benj Edwards
Senior AI Reporter